 Skip to content
Skip to content
Check out the project at https://library.groundmist.xyz
Cross-posted to my atproto PDS and viewable at Groundmist Notebook and WhiteWind
What if private data could be published effortlessly, without friction, fragmentation, or UI restrictions?
I’ve been experimenting recently with connecting local-first software to the AT Protocol (atproto). They share core ideals about user ownership and control, but they also offer different benefits as a result of their different approaches and goals. I was curious if combining them in a lightweight way would enable us to leverage some of the distinct benefits of each approach within the other context.
The local-first software movement is motivated by user-ownership and collaboration. Data lives on your device, enabling spinner-free interactions, yet it achieves this without locking you into any single specific device. Applications can be used while offline, without degrading the quality of the experience. Collaboration is seamless. Local-first data and local-first software operations mean security and privacy by default and greater user control. As a paradigm, local-first software provides a strong foundation for empowering users to have better software experiences and do more with our data.
The AT Protocol, on the other hand, is an “open, decentralized network for building social applications”. Although data is also user-owned, it is public and stored remotely in a Personal Data Server (PDS) which hosts your data repo, as well as signing keys. All of this is associated with a unique but portable user-owned identity.
A PDS, or Personal Data Server, is a server that hosts a user. A PDS will always store the user’s data repo and signing keys. It may also assign the user a handle and a DID.
https://atproto.com/guides/glossary#pds-personal-data-server
The AT Protocol champions interoperability and the idea of AppViews which provide flexible interfaces to interact with the canonical data stored in a user’s repo. This provides a flexible and verifiable foundation for users to consolidate their public data under a single public identity and present it in a variety of combinations and interfaces.
An AppView is an application in the Atmosphere. It’s called an “AppView” because it’s just one view of the network. The canonical data lives in data repos which is hosted by PDSes, and that data can be viewed many different ways.
https://atproto.com/guides/glossary#app-view
Although local-first software and AT Protocol have drastically different goals, they both offer us better ways of interacting with our data, one in the context of data that’s private or shared among small groups and the other in the context of public data. My first exploration came from the observation that many types of data have a lifecycle which begins as private but moves to public.
While I like local-first software for private or collaborative data, I find existing publishing patterns for local-first software to be too restrictive and to have unnecessary friction. I wanted to create a 1-click publishing pipeline to send local-first content directly to my PDS so that I can take advantage of the benefits of the local-first approach during the private stage of the data lifecycle but get all the benefits of atproto’s interoperability and flexible AppView interfaces once I’ve published my data to share with the world.
To explore this, I built a personal content curation app called Groundmist Library that takes this approach, with a 1-click publish to send any piece of content to your PDS. There’s a public view in the Groundmist Library app, but since the lexicon (atproto’s schema system) is published to the AT Protocol it’s simple to create alternative public AppViews, such as I’ve done in the “inputs” window at grjte.sh.
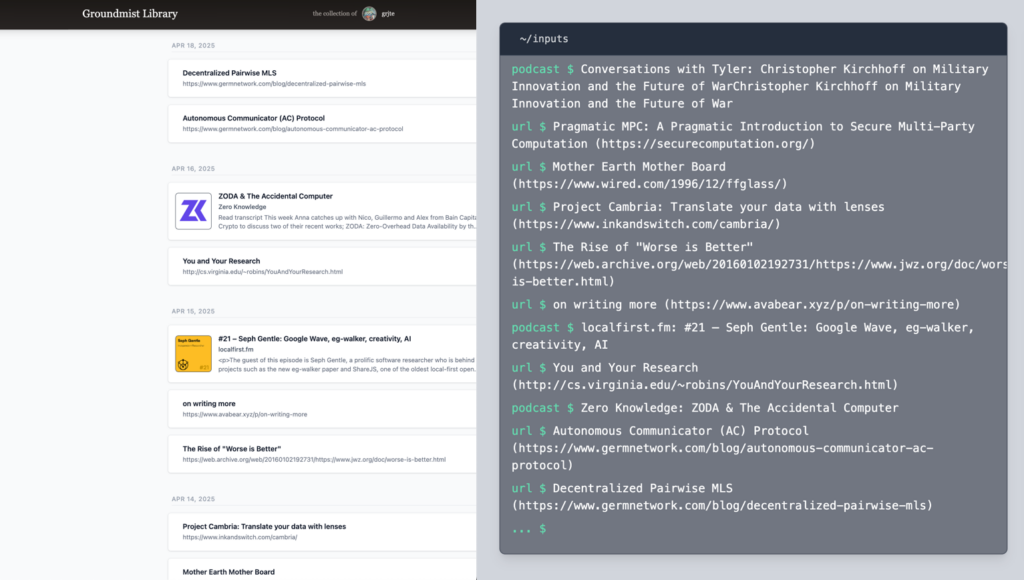
Groundmist Library: curate privately, publish effortlessly
Groundmist Library allows you to keep an archive of creative work you’ve read, watched, and listened to that was worthy of attention. The idea is to enable you to build a single unified historical view of the inputs that you found valuable across all types of content and then to be able to share a chosen subset publicly while keeping the rest private.
I wanted this personally for a few reasons:
- 1. To keep better track of high-quality content I might want to return to or reference later.
- 2. To look back at how I’ve spent my days, weeks, or months and where my attention was focused. I find this beneficial for inspiration, focus, and reflection.
- 3. To be able to effortlessly share my content history, but only a curated subset. Sometimes I want to track things that I’m not interested in sharing publicly, either because they’re not relevant to this facet of my identity or because they’re personal. My data should be private by default, but publishing a specific item of content should be frictionless.
- 4. To easily run local models over the history looking for trends, insights, and recommendations. Being able to simply connect and automate local models transitions the data from interesting for reflection to useful for personal behavioural feedback and future content selection.
Additionally, I love the idea of seeing a unified content history for people whose taste I appreciate and to see where our content consumption overlaps or differs. I enjoy looking at content recommendations like Tyler Cowen’s daily assorted links not just for the value of the content itself but also for the insights a person’s input choices give me into their thoughts and attention. I find it more interesting to see the shape of content consumption over time than to see recommendations in isolation. Finally, I like looking at a history of influential ideas and creative work separately from noisy discussion forums like X or Bluesky. It gives me space to explore my own thoughts before entering broader discussions.
For this project, I explicitly didn’t care about reviews or note-taking functionality. It’s intended for personal curation of high-quality content, so anything that’s not worthy of attention shouldn’t make the list, and notes on this kind of content would likely be better off on a platform designed for writing.
One-click publishing for local-first data
Many types of data have a lifecycle which begins as private but moves to public.
I described my reasons for wanting a simple private-to-public publishing pipeline for Groundmist Library above, but there are some general patterns that come up regularly:
- Public subsets: a private data set from which only selected items are shared. Groundmist Library is one example of this. Other examples where I want this are personal notes, where I may take many and share a few, creative work that requires practice to build skills, such as privately practicing art and publicly releasing a favourite piece or privately recording music in multiple takes and publicly releasing a single recording.
- Delayed release: private data becoming public at a future time. Examples of this pattern include drafting articles privately or collaboratively before publishing them, scheduling content for drip release or a specific launch date, or even live events within a game world which become part of the world’s public lore after they’ve completed.
- Public aggregated data: public views computed over private data. For example, someone may be interested in sharing information such as work patterns, energy levels, or health tracking in aggregate, but any specific data point is highly personal and might reveal more than they’re comfortable sharing.
Building a publishing pipeline to release this kind of data for any given project is straightforward. However, publishing processes vary across local-first applications, if they exist at all. They are often semi-manual (e.g. exporting each piece of data to a specific format and location), so that publishing requires effort, such as uploading or redirecting data to a specific location. When there are automated approaches, they tend to send data to an isolated and distinct public destination as an entire packaged website with a predefined structure and appearance, such as publishing to GitHub pages.
The result is that our public data is disconnected and fragmented as a function of its origin when it could instead be unified under a single public identity. This demands unnecessarily high effort for users who want to combine personal public data sets from multiple apps or display their data in different ways to the default view defined by the application.
Instead, I want a low effort, low friction way to publish my data to a unified data store from which I can display it flexibly in a variety of ways. The design of the AT Protocol around Personal Data Servers (PDSes) provides a place to unify public data, and their Lexicon schema system provides a structured way for software from different organizations to understand each others’ data, acting as a legibility layer that enables interoperation. This makes it easy to create new views over any combination of these public data sets.
How one-click publishing to atproto works
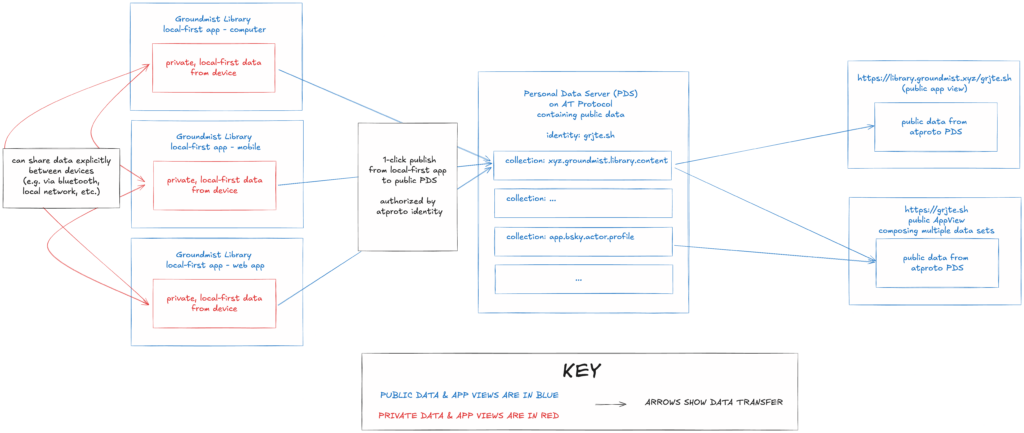
Adding a simple pipeline for a local-first application to publish globally to my PDS doesn’t require much. In order to enable interoperation and flexible interfaces, the AT Protocol specifies their Lexicon system for defining and publishing schemas. If an application is publishing data to a user’s PDS, that data must include an associated Lexicon id which defines its type. Organizations are highly encouraged (though not required) to publish their Lexicons to enable the interoperation benefits of the protocol.
To enable 1-click publishing for Groundmist Library, I did the following:
- 1. I created Lexicons for the various content types and published them in the Groundmist PDS. Typescript types that are generated from the Lexicons are used internally in the codebase for type-checking.
- 2. I added an atproto login and a publish button that simply posts the selected data to the user’s PDS using the atproto API library. This login is only used for publishing. Aside from the publishing path, the application is purely local-first.
- 3. I provided a default AppView for public data in the user’s PDS, in addition to the private view in the local-first part of the application. My personal public page for this AppView is here.
Because lexicons are public and have a defined resolution mechanism, it becomes easy to create a variety of public views over data that has Lexicon definitions. This gives the user more flexibility and control and could actually reduce the required work for the original application, since other projects (or AI agents) could take over creation and maintenance of public views. As an example of the flexibility of AppViews, you can see a different view of my public Groundmist Library data on my website, as shared earlier.
The diagram at the beginning of this section shows what this looks like for Groundmist Library. I’ve only created a web app, but in theory native apps could also exist. Content could be shared explicitly between different devices over various network transports in a typical local-first manner (Groundmist Library uses a sync server). Data can be published to the user’s data repo in their PDS with one click from any of these devices, as authorized by their atproto identity. From the PDS, the public data can be displayed in a variety of AppView interfaces.
Distribution for local-first software
Connecting a local-first application to the AT Protocol brings the benefits of atproto’s distribution to local-first software, both for users and for applications.
Leveraging the PDS for publishing local-first data not only enables greater flexibility and control for the user over how they use and present their public data, it also unlocks access to the distribution of the AT Protocol and its applications, such as Bluesky with its 30 million users. Published data can be cross-posted. It can be easily discovered and shared, and it can benefit from existing network connections, instead of each application needing to build a new social graph.
Beyond the distribution benefits for the user, there are distribution benefits for the applications. Lexicons which are published on the AT Protocol become part of a global schema network. Lexicon ids are namespace ids associated with a domain name, enabling structured schema discovery. For example, the lexicon id for Groundmist Library’s content record type is xyz.groundmist.library.content.
Thus, publishing lexicons on atproto gives applications a structured distribution network for their data schemas that has built-in schema resolution, promoting greater interoperability and visibility. Schemas which are reused in other contexts carry the name chosen by the original application, so applications also gain visibility as users publish application-generated data or as their public AppViews are shared.
Conclusion
Groundmist Library demonstrates a new pattern of local-first software architecture that enables effortless publishing, unifying public data from local-first applications under a public identity, and leveraging the distribution benefits of a social protocol with millions of users. It’s an example of the possibilities created by connecting the AT Protocol with the local-first software paradigm. You can use Groundmist Library to create your own personal collection, create or contribute to a shared collection, or explore the design in our GitHub.
Groundmist Library is the first in a series of explorations combining the local-first software paradigm with the AT Protocol. See more at https://groundmist.xyz
We welcome your feedback: @grjte.sh or grjte@baincapital.com.
Thanks to amplice, Kobi Gurkan, Alex Evans, and Goblin Oats for helpful feedback.