 Skip to content
Skip to content
Check out the project at https://notebook.groundmist.xyz
Cross-posted to my atproto PDS and viewable at Groundmist Notebook and WhiteWind
Some people like vim and some people like emacs and some people like something else, and why not have our documents able to be edited in all of those programs?
Seph Gentle on the localfirst.fm podcast
This is the second in a series of explorations around the possibilities we can unlock by connecting the local-first software paradigm to the AT Protocol (atproto). My motivation behind this exploration is captured well by a recent quote from Seph Gentle on the localfirst.fm podcast. As he points out, we’re accustomed to editing code across many editors–vim, emacs, and others–but in other disciplines our documents and data remain tied to single applications. The dream is to expand this editor flexibility to all of our data.
One of the most interesting features of the decentralized AT Protocol (atproto) is the flexibility it enables around how to interact with user data. The protocol has been designed to support and promote interoperation, enabling anyone to build a wide variety of different views over any of the public data repositories hosted in atproto Personal Data Servers (PDSes). These interfaces are known as “AppViews” because they provide just one of many possible views of the canonical data from the repo.
An AppView is an application in the Atmosphere. It’s called an “AppView” because it’s just one view of the network. The canonical data lives in data repos which is hosted by PDSes, and that data can be viewed many different ways.
https://atproto.com/guides/glossary#app-view
For example, different views of content I’ve recently curated and published to my data repo can be seen at my public Groundmist Library page or in the “inputs” window on my personal website. In addition to enabling different ways of interacting with data that originates in a single application, the atproto design enables AppViews to compose data from multiple application sources.
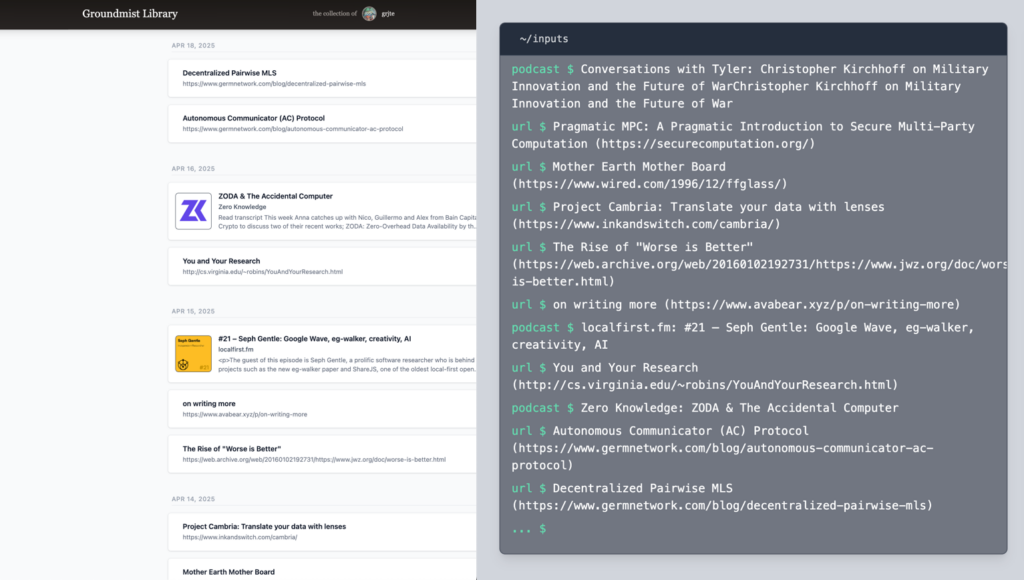
The AT Protocol design offers a powerful and flexible model for interacting with user-owned data. However, it was built for large-scale social applications, and all of the data on the protocol is public. For interacting with my own personal private data, I’ve been inspired by the local-first software movement, which also prioritises user ownership and control over data. The local-first software ideals include additional benefits like offline access, spinner-free interactions, and seamless collaboration. Unfortunately, the local-first software model doesn’t currently support data reuse with the ease and flexibility of the AT Protocol.
“Local-first software” [is] a set of principles for software that enables both collaboration and ownership for users. Local-first ideals include the ability to work offline and collaborate across multiple devices, while also improving the security, privacy, long-term preservation, and user control of data.
https://inkandswitch.com/local-first
For my next experiment combining local-first software with atproto, I wanted to explore the possibility of enabling local-first AppViews for local-first data, similar to atproto’s AppViews for public data, but without taking the data or associated software out of the local-first context.
To build a local-first AppView, I applied atproto’s Lexicon schema system to local-first software, since Lexicon is one of the main mechanisms for atproto’s interoperability. It provides a global network for agreeing on data semantics and structure that is separate from the data itself, which means it can be used even when the data isn’t available on the AT Protocol.
The project includes a local-first markdown editor that uses a public lexicon to define the document schema. The editor includes the ability to publish documents to your atproto PDS. I accompanied it with a public AppView for reading the published documents. These local-first markdown files could alternatively be edited in any other AppView that uses the same lexicon.1
Lexicons enable interoperability
What is Lexicon?
Lexicon is atproto’s schema system. It specifies a schema definition language alongside usage and publishing guidelines that enable a global schema network.
A global schemas network called Lexicon is used to unify the names and behaviors of the calls across the servers. […] While the Web exchanges documents, the AT Protocol exchanges schematic and semantic information, enabling the software from different organizations to understand each others’ data.
https://atproto.com/guides/overview#interoperation
The schema definition language provides a way to agree on semantics and behaviours and makes it simple for developers to introduce new schemas or safely reuse existing ones. Lexicons are JSON files associated with a single namespace identifier (NSID), such as app.bsky.feed.post. These NSIDs are used for organizing data within the PDS or retrieving data from collections, which are identified by the NSID.
The basic structure and semantics of an NSID are a fully-qualified hostname in Reverse Domain-Name Order, followed by a simple name. The hostname part is the domain authority, and the final segment is the name.
https://atproto.com/specs/nsid
Below is an example of a schema for record lexicon type from the atproto docs. Other types include query, procedure, and subscription.
{
"lexicon": 1,
"id": "com.example.follow",
"defs": {
"main": {
"type": "record",
"description": "A social follow",
"record": {
"type": "object",
"required": ["subject", "createdAt"],
"properties": {
"subject": { "type": "string" },
"createdAt": {"type": "string", "format": "datetime"}
}
}
}
}
}The Lexicon system also includes structured guidelines for how Lexicons should be published and resolved. This creates a global network of accessible and discoverable schematic information.
For example, the NSID of the primary lexicon for the Groundmist Library application is xyz.groundmist.library.content. The Lexicon record is published in Groundmist’s PDS at pds.groundmist.xyz and a DNS TXT record for _lexicon.library.groundmist.xyz specifies Groundmist’s DID so that the lexicon can be located.
Three benefits of Lexicon
The Lexicon system powers the interoperability of the AT Protocol. Lexicon creates a shared legibility layer between all servers on the network, which yields 3 major benefits:
- 1. Interfaces can be produced independently of servers, enabling enormous flexibility for how we interact with our data.
- 2. Rendering code (HTML/JS/CSS) doesn’t need to be exchanged. AppViews only need to know the data and the Lexicon schema definition (for understanding the data & interacting with it correctly).
- 3. The application doesn’t need a separate data store for simple AppViews displaying data from individual users. Creating and publishing these interfaces can be extremely fast and lightweight, since often no database or backend is needed.
This design enables high flexibility for interacting with user content. A multitude of different applications can be created for displaying or editing data from a user’s PDS, and the consistency of the underlying data is coordinated by adherence to the public Lexicons.
Does AI need schemas?
Before discussing the application of this model for interoperability to the local-first software context, it’s worth discussing the question of whether structured data still has value in a world of LLMs and sophisticated AI agents. Why not just let the models figure out what the data means and how to interact with it?
AI still needs structured data
Firstly, improved legibility improves the effectiveness of AI agents. Clear and consistent rules for understanding data semantics and structure make it easier for agents to interpret and work with the data in the ways that you expect and want. We get better results with less compute. In fact, Comind has begun exploring some of the benefits of using lexicons with AI.
Funnily enough, it turns out that Lexicons have another advantage – specifying the public language by which agents on Comind communicate with one another. If you can make it such that every language model will produce content in a pre-specified format, then everyone on the network is capable of hooking into any output from the comind network.
https://cameron.pfiffer.org/blog/lexicons-and-ai/
It’s still true that if all you ever want to do with your agents is let them read your data and create something new with it or provide insights, then letting the models “figure it out” is basically good enough. You might get better or faster results by having clearer semantics and structure, but you can still get where you want to go without it.
However, once we start imagining interactions that also modify our underlying data, reusing and changing it in different contexts, it becomes clear that we need some way for our agents and applications to coordinate.
Avoiding data fragmentation
Traditionally, reusing data often required exporting it from an application then importing it to a new application which has some custom importer code that processes the data so the new application can understand it. This results in a separate-but-similar data set for each application that interacts with the base data set. These separate near-duplicates naturally get out of sync and diverge from the base data set over time.
AT Protocol’s design enables data reuse without this sort of duplication, fragmentation, or divergence, making it possible to interact with our data in whatever way we find most effective or interesting in any given moment. This is because the canonical data always lives in a single place (the data repo in the PDS), and there are clear semantic and schematic rules for the names and behaviours of data. Every record has a single source of truth and is accompanied by the rules for how to interact with it, since the NSID of its lexicon is the name of its collection.
If AI agents naively read and modify data sets, writing the results to a new location associated with the current task or application, then we see a resurgence of the same problem that atproto solved. Data is duplicated unnecessarily and gets out of sync (unless some sort of syncing system is introduced, which also requires coordination).
On the other hand, if AI agents read and modify data sets, writing back to a canonical location, then we need guarantees that when the data is modified the result still conforms to our expectations and the data will still be usable within its original context and any contexts that use the same data. A schema system enables us to use validation and have guarantees that when data is modified the result is still valid and legible, regardless of how many agents have interacted with the data or what they use it for.
Humans still need legibility
The final simple reason that using a system for legibility and coordination is still beneficial in an AI-dominated world is that at some point we may as humans want to read some of our data directly ourselves. As Andy Matuschak notes in a recent post about generating malleable software with LLMs:
I think that our understanding bounds the complexity of systems we can create—even if an LLM is doing the programming. If we can’t really understand a system’s behavior, except through trial and error every time a change is made, problems and confusions will pile up. It will become more and more difficult to change the system predictably.
Andy Matuschak
Using a consistent system means that no matter what interactions occur with AI agents, we can still understand, access, and analyse the output.
Building a local-first “AppView”
Although Bluesky is the most well-known social application on the AT Protocol, there is enormous scope for variety, recreating familiar settings or creating entirely new ones, all while leveraging the underlying network connections and the shared interoperability layer.
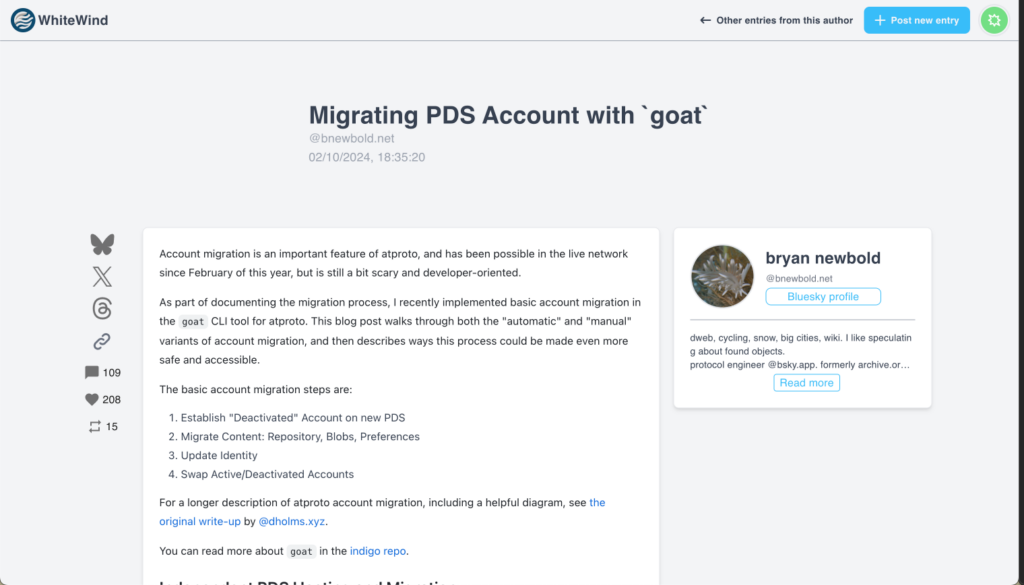
Introducing WhiteWind
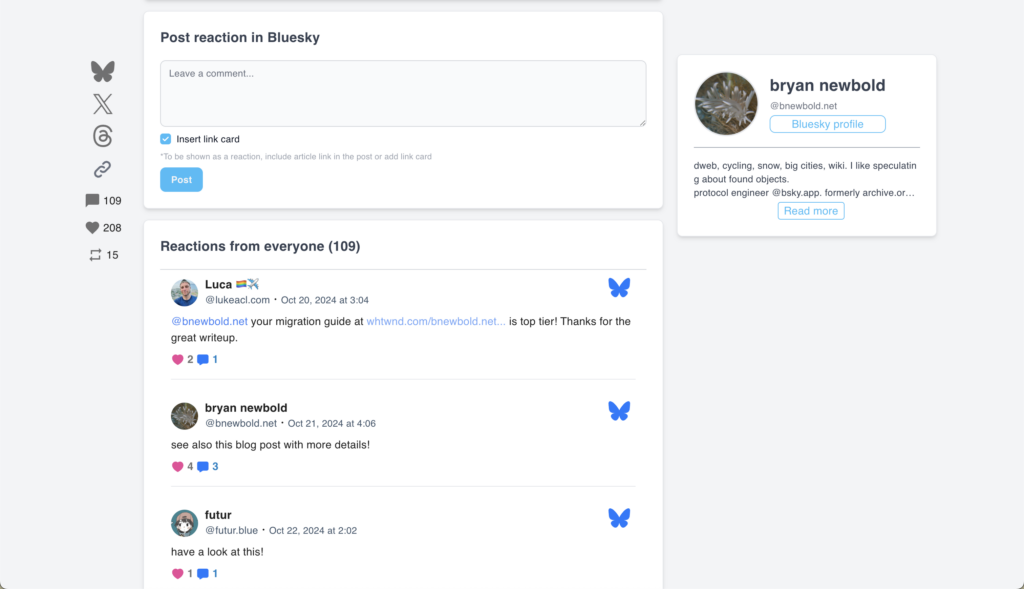
One interesting project that has explored this area is WhiteWind, which is a blogging platform for markdown content that is built on top of the AT Protocol. WhiteWind brings the familiar blogging experience to atproto but additionally leverages the protocol’s interoperability to add an interesting twist – comments on blog posts are also threads in Bluesky.
Privacy challenges
WhiteWind demonstrates many of atproto’s benefits, but it is also a case study in one of the challenges of building on the AT Protocol – all your WhiteWind entries are publicly readable, even if you haven’t published them yet, since all data on atproto is public.
WhiteWind tries to work around this by adding a “visibility” field to the lexicon specifying whether data should be either public, viewable if you know the URL, or only for the logged-in author. The hope is that all AppViews will respect this field and that no person (or AI) will query and look at data where “visibility” isn’t “public”. Here is the WhiteWind blog entry lexicon, showing this method of handling private/public data visibility:
{
"lexicon": 1,
"id": "com.whtwnd.blog.entry",
"defs": {
"main": {
"type": "record",
"description": "A declaration of a post.",
"key": "tid",
"record": {
"type": "object",
"required": [
"content"
],
"properties": {
"content": {
"type": "string",
"maxLength": 100000
},
"createdAt": {
"type": "string",
"format": "datetime"
},
"title": {
"type": "string",
"maxLength": 1000
},
[...fields excluded for brevity...]
"visibility": {
"type": "string",
"enum": [
"public",
"url",
"author"
],
"default": "public",
"description": "Tells the visibility of the article to AppView."
}
}
}
}
}
}Unfortunately, asking people to follow gentlemanly guidelines and “just not look” is the kind of request that good actors comply with and bad actors and agents ignore. We can’t realistically expect compliance. However, a local-first AppView for editing could offer us a way to avoid the problem altogether!
Introducing Groundmist Editor & Notebook
To explore this idea, I created Groundmist Editor2 a simple local-first writing tool for drafting and collaborating on markdown documents and then publishing them when ready. It uses the WhiteWind blog entry lexicon com.whtwnd.blog.entry, making it simple to create alternate interfaces for interacting with the same local data or to create additional interfaces composing this data with other personal data, such as analysing the number of updates I made in a week against the amount of sleep I got.
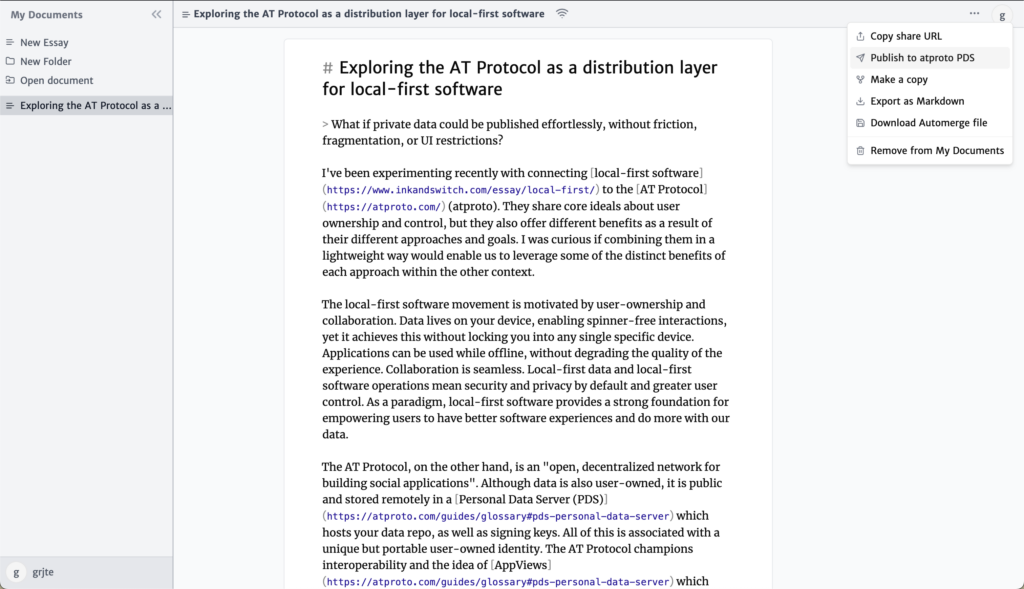
To make publishing single documents effortless, I used atproto as a distribution layer by publishing documents to the user’s atproto PDS, as I outlined in my previous post.
Because I used the existing WhiteWind lexicon, documents are published to the com.whtwnd.blog.entry collection on atproto, which means that WhiteWind acts as a public AppView for published entries. This also means that Groundmist Editor functions as a private editor for drafting WhiteWind blog posts, instead of them being publicly retrievable from the user’s PDS.
Because I wanted a simple and minimally-distracting interface for reading, I also created an alternative AppView for viewing published writing called Groundmist Notebook, which provides a basic view of the content without WhiteWind’s interactivity features. All WhiteWind blog entries and all entries published from the Groundmist Editor can be read there in addition to on WhiteWind.

The interoperable system
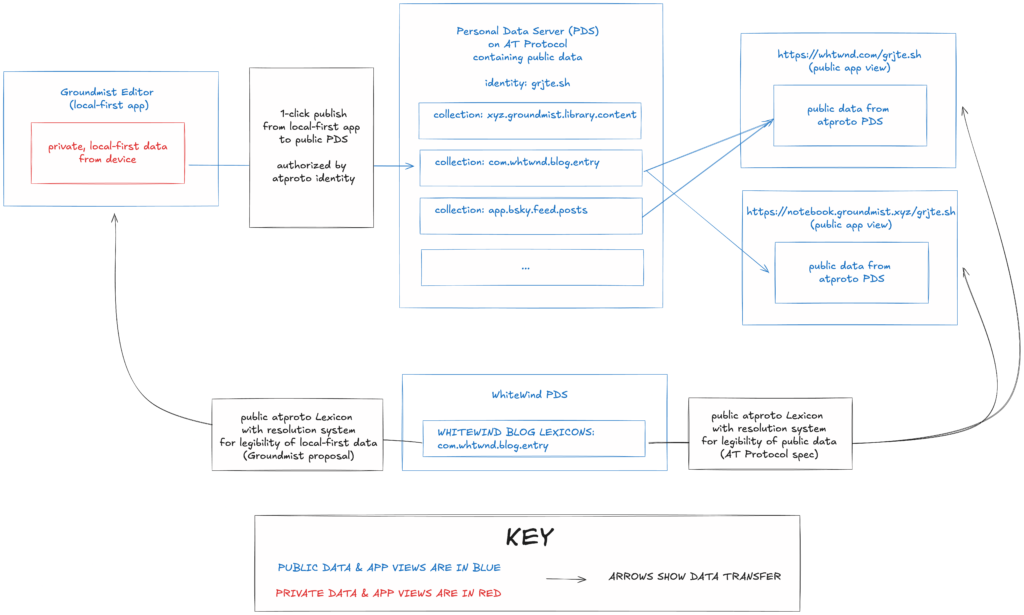
The full setup for this exploration consists of one public lexicon (com.whtwnd.blog.entry, created by the WhiteWind team) and three public AppViews:
- 1. Groundmist Editor, the local-first AppView for drafting and collaborative editing (forked from the Ink & Switch team’s “tiny essay editor” then minimally modified)
- 2. Groundmist Notebook , a public AppView for reading published content on AT Protocol
- 3. WhiteWind, the original AppView for reading published content with this lexicon and interacting with it on Bluesky, created by the WhiteWind team
The diagram above shows what the system looks like with all three AppViews and the lexicon. Groundmist Editor uses a sync server (not shown) so that content can be shared between different devices by sharing the document link. Documents can be published to a user’s data repo in their PDS with one click, as authorised by their atproto identity. From the PDS, the public data is displayed in both Groundmist Notebook and WhiteWind. All three of these AppViews share a single lexicon.
Vision: an interoperable local-first ecosystem
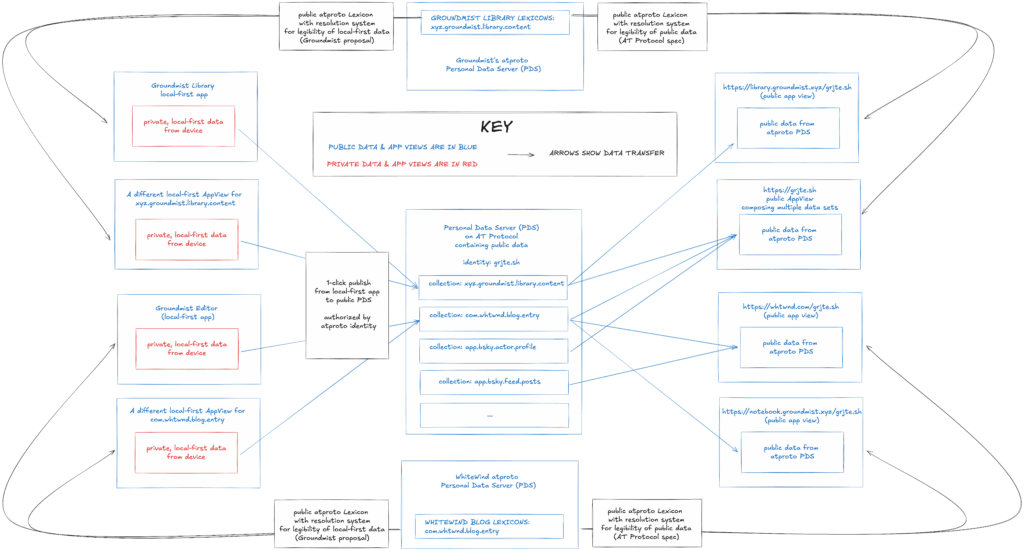
A first model for using local-first AppViews
The Groundmist Editor/Notebook project demonstrates one model for using local-first AppViews: local-first software applications can provide AppViews of private data and be connected via a lexicon to public AppViews that display data that was published to the AT Protocol.
Local-first software applications can provide AppViews of private data and be connected via a lexicon to public AppViews that display data that was published to the AT Protocol.
This enables a private software layer for the AT Protocol that in the long run will offer better UX than simply adding private data to the PDS, since it offers benefits of local-first software such as low latency and offline capability.
A second model for using local-first AppViews
There’s a second interesting model for using local-first AppViews, which is to have a local-first ecosystem where local-first applications are connected by shared lexicons and data sets but operate independently. In this world, local-first software applications can provide multiple AppViews for private data that never gets published. This enables the same interface flexibility for interacting with local-first data that we experience when interacting with public data on atproto. It offers a way to achieve the dream of collaboration over a data set without being required to use the same application or interaction mode.
Local-first software applications can provide multiple AppViews for private data that never gets published. By using shared lexicons and data sets, independently operating local-first applications can form a local-first ecosystem.
As a motivating example, one thing I particularly want is more flexibility when interacting with all of my linked notes and writing, which are currently spread across Obsidian and Logseq (and more). I like Logseq’s structure (1 bullet point per line) for thinking, tracking my days, and connecting ideas, but I often want to write something longer form, which is better suited to Obsidian or a similar markdown editor. With the ease of creating LLM-generated software, I would ideally like to create custom personal interfaces for interacting with different types of writing and notes, while still keeping it in a unified home and having a single application that knows how to interact with all of it at once.
The Lexicon schema network offers a solution, since it could be used to provide a global layer that shares semantics and behaviour for local-first data and software. This would simplify creating new AppViews and ensure data consistency without requiring the data itself to be public or available. For general use, these interfaces will be local-first applications that can function offline, because Lexicon definitions are mainly needed when new AppViews are being created or at discrete update points.
This provides a public legibility layer over private data and enables the interoperability of the AT Protocol within the local-first software context.
A note on schema lenses
The idea of strictly using Lexicon for defining local-first data will inevitably be too restrictive in some cases. As applications develop and schemas change there are challenges around interacting with older and newer versions of data.
Additionally, a lexicon for public data may not match the one desired for private data. Even in the simple Groundmist Library application from my first Groundmist post these types differed slightly, as I couldn’t post the automerge urls of documents publicly to a user’s PDS without making those documents editable to anyone (since it uses a version of Automerge without an authorization layer).
Ink & Switch has done interesting work in this area with the Cambria project and their research into data lenses. In a case like this slight mismatch between public and private data, an ideal solution might be a publicly defined “data lens” that describes how to consistently transform a public lexicon to a private schema (e.g. add a field for the Automerge url).
The global schema network provided by Lexicon is extremely powerful, and exploring similar ways to manage and share data lenses would be an interesting area of future work. This idea of “Lexicon Lenses” is a project that the community has recently begun to work on.
Conclusion
Groundmist Editor explores the idea of flexible local-first AppViews over canonical data sets and the possibilities for interoperability, composability, and doing more with our data that we can unlock by leveraging atproto’s global Lexicon network for local-first software. It’s an example of how we can improve existing atproto applications and hints at how we could expand the world of local-first software into an interoperable ecosystem.
As a final note, you may have noticed that in order to realise these ideas about local-first AppViews and local-first data composability the legibility that I discussed in this post is required but not sufficient. We also need some way for local-first applications to locate and access these data sets. Groundmist is a series of progressive experiments combining the local-first software paradigm with the AT Protocol, and the next exploration will focus on this challenge.
If you’re interested in these ideas or the possibilities of combining local-first software with the AT Protocol, please reach out to me on Bluesky.
We welcome your feedback: @grjte.sh or grjte@baincapital.com.
Thanks to Goblin Oats and Blaine Cook for helpful feedback on this work.
- 1. Note: I used the Automerge CRDT library for local-first data management. In addition to conforming to the lexicon, alternative local-first AppViews would need to be able to interoperate with these data structures, e.g. by also using Automerge. ↩︎
- 2. Forked and modified from https://github.com/inkandswitch/tiny-essay-editor, an existing a local-first markdown editor. ↩︎